


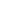
Базы данных
База данных (Data Base) – это собрание таблиц, в которых содержатся наборы данных. В них есть колонки с наименованиями параметров и строки, в которых указаны величины различных сущностей (например, «заказ», «клиент» и т.п.) для каждой колонки. Работа с таким базами данных возможна при помощи языка структурированных запросов SQL (Structured Query Language). Этот язык является средством коммуникации с системой управления базами данных СУБД (RDBMS – Relational Data Base Management System). SQL содержит команд, которые позволяют создавать, хранить, изменять и использовать данные из таблиц в базах данных.
")
Рис. 1. Пример базы данных для работы ресторана (источник: bd-subd.ru)
SQL представляет собой промышленный стандарт, который был разработан Международной организацией по стандартизации ИСО (International Organization for Standardization, ISO). Этот стандарт постоянно пересматривается, в него вносятся одни элементы и исключаются другие.
В различных продуктах используются различные версии («диалекты») языка SQL, и таких диалектов существует довольно много. Это объясняется тем, что в базовом стандарте ISO отсутствуют некоторые необходимые для практической реализации элементы, например, индексирование.
SQL Server
В 1980-х годах компания Sybase разработала систему управления базами данных под названием SQL Server для мини-компьютеров с операционной системой Unix. Персональные компьютеры тогда только входили в обиход, но мало кто мог использовать их возможности, по причине недостатка прикладных программ. Поэтому, Sybase в сотрудничестве со стартапом Ashton-Tate, в котором была разработана СУБД Dbase и компанией Microsoft портировала свой продукт на архитектуру персонального компьютера. В то время в качестве операционной системы для ПК использовалась OS/2 (получившая шуточное название «полуось» в среде российских ИТ-специалистов). Версии SQL Server для ПК-серверов на OS/2 носили порядковые номера 1.0, 1.1 и 4.2.
Затем компания Microsoft разработала ОС Windows NT и SQL Server был портирован на это новую и быстро завоевывавшую популярность операционную систему. В 1992 году, вскоре после выхода Windows NT, Microsoft выпустила SQL Server 4.2 , которая предназначалась изначально под OS/2, но, поскольку стало ясно, что Windows гораздо более популярно, то её переделали для Windows NT.
Затем Microsoft дистанцировалась от Sybase и разработала свой собственный SQL Server. Именно по этой причине, сейчас, когда говорят SQL Server, чаще всего имеется в виду Microsoft SQL Server. Позднее были выпущены версии 6.0 и 6.5, в которых, однако, принципиально новых изменений не содержалось.
Затем в 1998 году Microsoft полностью переписала код своего продукта SQL Server, новая версия получила номер 7.0. Целью этой работы было обеспечение будущей совместимости с системами хранения, которые могли появиться в следующие 20-30 лет. В целом, новая архитектура была довольно успешной. Был добавлен Microsoft OLAP Server (Online Analytical Processing, интерактивная аналитическая обработка) при импорте и экспорте данных. Данные в реляционных базах данных хранятся в отдельных таблицах. Эта структура удобна также для операционной обработки транзакций OLTP (Online Transaction Processing), однако, многотабличные запросы в ней выполняются относительно медленно.
OLAP-структура создаётся из соединения таблиц по схеме звезды или снежинки (OLAP-куб). В центре схемы находится таблица ключевых фактов, по которым делаются запросы. Подключенные таблицы показывают, как могут анализироваться агрегированные данные. Такая структура позволяет повысить скорость анализа данных.
В следующей версии SQL Server 2000 был также добавлены сервисы отчётности (Reporting Services).
В версии SQL Server 2005 также были внесены изменения, хотя и не такие существенные как в 7.0. Одним из значительных изменений была полностью обновленная структура мета-данных, в которой Microsoft полностью изменила структуру таблиц, перейдя от их физической структуры к абстрагированному виду, где физическая структура таблиц пользователю не видна. OLAP Server был переименован в Analysis Services, а набор сервисов преобразования данных DTS (Data Transformation Services) – в SQL Server Integration Services (SSIS). Код этих компонентов был полностью переписан.
Более новые версии SQL Server: 2008 R2, 2012, 2014, 2016, 2017 представляли собой эволюционное изменения версии 2005. Однако, последняя на данный момент версия Microsoft SQL Server 2019, представляет собой качественно новый этап в развитии систем управления базами данных, которые предназначены больших неструктурированных данных (Big Data) объёмами в несколько петабайт и более.
T-SQL
T-SQL (Transact-SQL) – процедурный язык Microsoft, расширение для SQL Server. Он содержит команды REPL (Read-Eval-Print-Loop), которые расширяют стандартные команды SQL для манипулирования данными DML (Data Manipulation Language) и описания данных DDL (Data Definition Language). Функции управления представляются в виде системных процедур, которые можно запускать из запросов T-SQL, что также позволяет цепочку связанных серверов (Linked Servers). При этом, один запрос может быть обработан сразу на множестве серверов.
Сравнение версий
Компания НРЕ провела сравнение скорости работы версий SQL Server 2014 Standard Edition и SQL Server 2019 Std Edition на своих серверах серии HPE DL380, которые чаще всего выбирают заказчики как сервер баз данных SQL. Они показали в несколько раз более высокое быстродействие SQL Server 2019 по сравнению с предыдущими версиями.
.")
Рис. 2. Сравнение скорости работы SQL Server 2014 и SQL Server 2019 (источник: НРЕ).
Microsoft SQL Server 2019 для кластеров больших данных (Big Data Clusters)
В условиях, когда объёмы хранимой в базах данных информации растут экспоненциально и достигают объёмов пета- и эксабайт, становится весьма трудно их анализировать и получать полезные выводы (инсайты) на основе такого анализа.
Хотя SQL Server непрерывно развивается, он не был рассчитан ни на работу для аналитики данных таких объёмов, ни на хранение и анализ данных неструктурированных форматов, таких как медиа-данные (изображения, аудио, видео и пр.).
Введение механизма кластеров больших данных (Big Data Clusters) в SQL Server 2019 решает проблемы обработки больших массивов данных (пета- и эксабайт), а также повышает гибкость обработки при помощи механизма унифицированной аналитики больших объёмов данных Spark.
В кластерах больших данных на SQL Server 2019 могут работать сразу несколько экземпляров SQL Server с сервисом очистки (ingest) данных Spark и распределённой файловой системой для больших данных HDFS (Hadoop Distributed File System). Они объединяют реляционные и большие неструктурированные данные, используют их в отчётах, предиктивных моделях и приложениях искусственного интеллекта.
При помощи Transact-SQL (T-SQL) или Spark (комплекс программ с открытым исходным кодом для реализации распределённой обработки неструктурированных и слабоструктурированных данных, входящий в экосистему проектов Hadoop), можно комбинировать и анализировать реляционные таблицы данных и большие неструктурированные данные (Big Data). Использование HDFS создаёт эластичную СХД, которая может масштабироваться до уровня петабайт. Механизм Spark обрабатывает и анализирует большие объёмы данных в распределённой компьютерной среде с вычислениями в памяти (in-memory).
Архитектура кластера Big Data
Как и многие другие реляционные базы данных, ранее в SQL Server необходимо было наращивать вычислительные мощности, чтобы повысить объёмы обрабатываемых данных. Поэтому, сегодня многие физические серверы, на которых работает SQL Server, работают на пределах своих возможностей.
В кластере Big Data на SQL Server 2019 используются технологии обработки больших данных, поэтому как производительность вычислений, так и объёмы хранения, могут расширяться независимо.
Добавление поддержки работы в среде Linux в SQL Server 2017 открыло возможности глубокой интеграции SQL Server со Spark, HDFS и другими компонентами больших данных, которые изначально работали в Linux.
.")
Рис. 3. Архитектура кластера Big Data на SQL Server 2019 (источник: Microsoft).
Кластер больших данных – это вычислительный кластер из контейнеров, где работают SQL Server и сервисы Big Data, который оркеструется основным сервером SQL Server (Master). В каждом кластере SQL Server, Spark и HDFS реализованы на контейнерах Kubernetes, поддерживаемых Microsoft.
Kubernetes – это open-source-платформа оркестрации, которая облегчает развёртывание логических групп контейнеров, называемые «подами» (pods), которые являются базовыми строительными блоками Kubernetes.
Каждый под работает на узле, который может быть либо физической, либо виртуальной машиной в Kubernetes. Каждый узел поддерживается «мастером». В узле может быть множество подов и мастер Kubernetes автоматически назначает поды узлам в кластере. При этом, когда мастер делает назначения, он автоматически учитывает все доступные ресурсы на узле.
Кластер больших данных на Kubernetes можно развёртывать быстро, предсказуемо, и с возможностью дальнейшего эластичного масштабирования ресурсов, вне зависимости от местоположения.
Кластеры больших данных обеспечивают средства и системы для извлечения, сохранения и подготовки данных для последующего анализа, для обучения моделей нейросетей, а также они могут сохранять эти модели и обеспечивать работу законченных платформ искусственного интеллекта AI (Artificial Intelligence).
.")
Рис. 4. Законченная платформа AI на базе кластеров больших данных SQL Server 2019 (источник: Microsoft).
Таким образом, мы видим, что концепция SQL Server, разработанная почти 50 лет назад, сегодня активно развивается, в том числе для кластеров больших данных. Это позволяет использовать накопленные ценные данные из реляционных баз данных вместе с огромными массивами больших неструктурированных данных на основе унифицированной масштабируемой платформы.
Предприятия и организации могут использовать механизм PolyBase для объединения разных форматов данных, виртуализации хранилищ данных, создания «озер данных» (data lake) и построения продвинутых систем аналитики и искусственного интеллекта с возможностями машинного обучения. Они могут обеспечить гораздо большую эффективность и безопасность работы с данными на предприятии, чем медленные и дорогие системы сбора данных ETL (Extract, Transform, Load) — «извлечение, преобразование, загрузка»), которые использовались ранее.


