


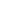
Если погуглить по ключевым словам «объектные системы хранения» или object storage, то можно найти много текстов, объясняющих, что такое объектное хранилище и как оно работает, как объектные системы опережают в росте объемов другие типы систем хранения: блочные и файловые. Но мало кто говорит, чем такой рост вызван, какие практические преимущества могут дать ИТ-бизнесу объектные системы хранения, для решения каких проблем они создаются.
Чтобы избавить вас от попыток составить единую картину из разрозненных фактов, которые к тому же надо искать преимущественно в англоязычных источниках, мы постараемся дать краткое и, по возможности, полное объяснение, что такое объектные системы хранения, зачем и в каких случаях они нужны.
Зачем?
Не секрет, что рост объемов хранимых данных в последние годы происходит экспоненциально. По результатам опроса, проведенного исследовательской компанией «451 Research» в 2017 году, более 60 % организаций заявили, что объемы их систем хранения превышают 50 Петабайт, и процент их роста выражен двузначной цифрой. Если читатель работает инженером по системам хранения, ему не нужно объяснять, что традиционные системы хранения (блочные и файловые) просто не рассчитаны на такие темпы роста объемов данных, которые нужно надежно хранить и защищать.
Объемы хранимых данных (источник: 451 Research, Western Digital, 2017 г.)
Традиционный подход
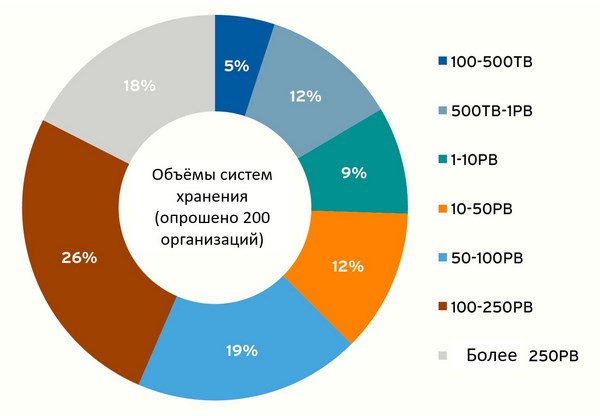
Традиционный подход к хранению данных – системы SAN (Storage Area Network) или NAS (Network attached Storage), если не рассматривать совсем простые системы DAS (Direct Attached Storage) – это, например, внешняя дисковая полка, подключенная напрямую к RAID-контроллеру сервера.
Различия SAN и NAS
Такой метод подойдет при относительно небольших объемах хранения. При росте дискового хранилища возникают проблемы с файловой системой. Традиционные файловые системы разбивают каждый файл на маленькие блоки, обычно объемом 4 килобайта, и сохраняют месторасположение каждого блока в таблицах просмотра (lookup table) файловой системы. Для небольших объемов данных это хорошо, но как только вы расширите систему хранения до петабайта и больше, таблицы станут непомерно огромными. Это сильно замедляет поиск нужного блока и увеличивает возможность ошибок.
Поэтому пользователи вынуждены разбивать свои наборы данных на многочисленные логические узлы LUN (Logical Unit Number), чтобы как-то поддержать быстродействие на приемлемом уровне. Однако при этом значительно увеличиваются сложность и затраты на администрирование и поддержку ИТ-системы, а проблемы быстродействия, потери данных и простои системы сказываются на бизнес-процессах.
Распределенная файловая система
Для решения этой проблемы стали использовать так называемые горизонтально-масштабируемые (Scale-out) файловые системы, такие как HDFS (Hadoop Distributed File System). Это распределенная файловая система на базе Hadoop, свободно распространяемого набора утилит для создания распределенных систем, работающих на кластерах из сотен и тысяч узлов. Проблема масштабирования при этом решается, однако поддержка таких систем также довольно трудоемка. Они конструктивно сложны и требуют постоянного обслуживания. К тому же в них чаще всего используется механизм репликации данных, то есть попросту хранения копий одних и тех же данных в разных местах системы. Стандартно сохраняются три копии каждого файла. Излишне говорить, что это увеличивает требуемый дисковый объем на целых 200 %! Хотя цены на диски все время снижаются, но объемы данных, которые необходимо хранить, растут еще быстрее. Это напрочь съедает экономию на недорогих дисках. Для петабайтов информации такой подход неприемлем.
Облачное хранение
Для минимизации этих проблем многие стали прибегать к использованию облачных хранилищ. Модель оплаты по мере потребления (pay-as-you-go) работает отлично, но опять-таки – для относительно небольших объемов данных и при нечастом их использовании. При постоянном масштабировании объемов данных, интенсивной работе с ними этот подход также становится весьма затратным, не дешевле HDFS. Дело в том, что многие облачные провайдеры берут плату не только за объем хранимых данных, но и за трафик извлекаемых/записываемых данных, а также и за число транзакций (обращений) к хранилищу. Поэтому, когда приходится иметь дело с анализом больших данных, передачей массивных объемов данных, то хранилище в публичном облаке – наверное, самый дорогой подход. Кроме того, могут возникнуть проблемы конфиденциальности данных и производительности системы, если много других пользователей также будут интенсивно использовать ресурсы данного облака.
Что делать?
Выходом в такой ситуации может быть объектная система хранения (object storage), в которой используются примерно те же технологии, что в публичном облаке (HTTP, API). Объектные хранилища можно легко масштабировать до объемов петабайта в одном домене, без какой-либо деградации производительности. Кроме того, объектные хранилища имеют функционал управления данными, чего нет в традиционных системах: управлении версиями, кастомизации метаданных и встроенной аналитике.
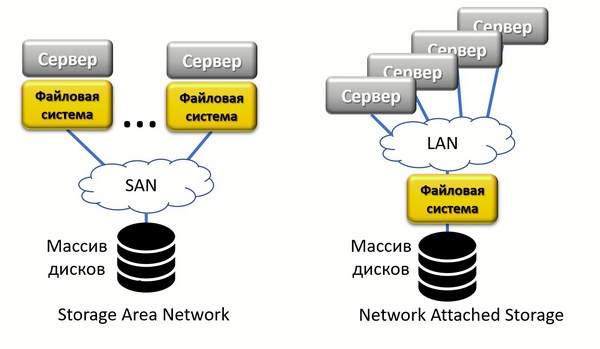
Такие характеристики достигаются за счет абстрагирования уровней системы – общий подход, который сейчас используется практически во всех ИТ- и телеком-системах, не только в системах хранения. Каждый диск на нижележащем уровне форматируется простой локальной файловой системой, такой как EXT4. На верхнем уровне, абстрагированном от нижнего, размещаются средства управления, что позволяет интегрировать все элементы в едином унифицированном томе. Файлы различного вида хранятся как «объекты», а не как файлы в файловой системе. Поскольку низкоуровневое управление блоками передано локальной файловой системе, объектное хранилище ведает только функциями управления высокого уровня, которые управляют нижележащим уровнем через стандартный интерфейс прикладного программирования API (Application Programing Interface).
Объектная система хранения
Принцип объектного хранения можно сравнить с услугой парковки, когда вы просто оставляете машину (объект) для ее размещения на парковочном пространстве и получаете карточку, по которой вы можете получить машину обратно. В карточку могут быть внесены «метаданные»: ваше имя, номер и марка машины. Где именно запаркуют машину, вам неинтересно (абстрагирование), и вам не нужно кружить по парковке в поисках свободного места.
Такой подход позволяет сохранять таблицы просмотра файловой системы каждого узла нижележащего уровня в пределах легко управляемого размера. Это позволяет масштабировать систему до сотен петабайт без заметного снижения производительности.
Структурированные и неструктурированные данные
Понятие «структурированные» и «неструктурированные» данные – весьма относительно. Все файлы с данными имеют ту или иную структуру, тип файла. Поэтому, с этой точки зрения, все файлы – структурированные. Когда говорят, что данные – неструктурированные, имеется в виду, что они не хранятся в единой базе и содержат разные типы данных. Это просто набор разнородных файлов, созданных в различных приложениях и полученных из разных источников. Если открыть на компьютере папку «Мои документы», то примерно это там и будет.
Объектное хранилище предназначено в основном для работы с неструктурированными данными. Объекты неструктурированных данных можно пометить метаданными, которые описывают их содержимое и помогают быстро извлечь из хранилища нужный объект. В этом случае сами метаданные будут структурированы, т. е. будут иметь стандартную форму, определенную в API. Это позволяет отслеживать и индексировать объекты, без необходимости применять внешние программы или базы данных. Использование метаданных открывает новые возможности для аналитики. Файлы (объекты) можно индексировать и искать в объектном хранилище, не зная структуру их содержимого или того, в какой программе они были созданы.
Защита данных
Нужна ли репликация данных для надежного хранения в объектной системе? Да, нужна, но при этом не требуется утраивать объем дискового пространства, как в блочной системе. Для максимизации доступного дискового пространства и защиты данных используется технология Erasure Coding (ЕС). Упрощенно ее можно назвать следующим поколением хорошо известного метода защиты данных RAID, при котором необходимо двойное или тройное резервирование.
В методе ЕС файлы объектов разделяются на фрагменты (shards). Для некоторых из них создаются копии избыточности в формате N+M. Например, если для шести из десяти фрагментов создаются копии, это будет формат 10+6. Данные, для которых нужно, например, N дисков, копии избыточности распределяются по N+M дискам (в данном случае 16). При потере любых шести дисков, оставшихся десяти достаточно для восстановления исходных данных. Таким образом, избыточность объема хранения получается не такой большой, как в RAID, и она может противостоять множественным отказам дисков без риска потери данных. Тома ЕС могут выдерживать больше отказов дисков, чем дисковые массивы RAID. При этом петабайтное масштабирование системы не будет приводить к столь большим затратам на закупку дисков, как в файловых системах.
Для чего?
Объектное хранилище часто выбирается для данных WORM, которые пишутся один раз, но читаются много раз (Write Once Read Many). Оно подходит не для всех объемов данных и сценариев использования, но, безусловно, имеет много применений.
Объектные системы хранения целесообразно использовать в следующих случаях:
- Долгосрочное хранение статичных данных, например, различной нормативной документации (WORM).
- Резервные копии – дампы баз данных, файлы журналов, резервные копии существующего программного обеспечения.
- Среда разработки DevOps – одно глобальное пространство имен, которое легко доступно с использованием простых запросов для управления различными объектами: большими базами данных, таблицами, изображениями, звуковыми и видеофайлами и пр.
- Неструктурированные данные – мультимедийные файлы, документы, изображения, звуковые и видеофайлы
- Отрасли с большими объемами хранения данных, такие как:
- Здравоохранение – электронные медицинские записи, цифровые изображения, данные системы PACS;
- Финансово-торговые платформы, электронная почта, мессенджеры, оцифрованные архивы музеев, конструкторских бюро и т. п.
- Статический веб-контент – большие объемы HTML-файлов и изображения для сайтов.
Таким образом, мы видим, что объектные системы хранения хорошо подходят для хранения массивных разнородных (неструктурированных) данных и отвечают запросам бурного роста объемов данных, которые нужно хранить, обрабатывать и анализировать в различных отраслях. Именно поэтому объемы объектных систем хранения растут значительно быстрее объемов файловых систем.
***
В следующей статье мы представим обзор рынка объектных СХД на примере популярных систем объектного хранения:
- Dell EX3000D, недорогую многоцелевую систему хранения высокой плотности, которую можно использовать как программно-конфигурируемую распределенную систему хранения (SDS), как гиперконвергентный узел и как основу для создания облачной эластичной системы хранения (ECS);
- Western Digital ActiveScale, объектное хранилище неструктурированных данных, начиная с полезной емкости 500 ТБ до нескольких десятков петабайт в едином пространстве имен, которое оптимизирует использование хранилища в средах со смешанными нагрузками;
- IBM Spectrum Scale, систему управления хранилищем с поддержкой горизонтального масштабирования, которая служит основой унифицированного подхода к поддержке виртуализации, аналитического окружения, работы с файлами и объектами, которая предназначена для поддержки приложений с большими объемами данных (например, репозиториев контента и систем анализа больших данных).
Алексей Шалагинов, ИТ-эксперт ITELON


